Web数据采集系统
Web数据采集系统是基于网络爬虫技术的大数据获取与分析方案。
在互联网与大数据时代,任何企业均可从数据采集与分析中获益。
Web数据采集系统基于先进的分布式网络爬虫框架技术,为企业量身定制全面、精确的数据采集方案,协助企业获得海量信息数据并加以深度分析、科学统计,协助企业制定战略规划,分析竞争对手,捕获客户属性,真正将信息与数据转化为生产力。


功能&特点
高级功能
输入网址即可采集
只需要输入采集目标的网址,即可完成采集的设置。系统会自动分析出内容页面的标题、正文、时间、作者、来源等关键事项。
输入关键词即可采集
只需要输入需要采集的关键词,即可完成采集的设置。系统会自动向所有的中文搜索引擎提交这些关键词,并将搜索结果自动采集下来。
云采集功能
基于对等网(P2P)架构的云计算,将所有在线的熊猫软件的计算机联网成一个虚拟的超级计算机。每个熊猫端可以是请求端,也可以是协助端。
过滤重复数据
对采集结果文章分词结果建立索引,然后依据新的文章的分词结果快速检索到相似文章。
多模板功能
一个采集项目,可以配置多个内容页面模板,运行时软件自动选择最合适的模板来进行采集匹配。
可视化发布
直接利用网站现有的人工发布页面进行模拟人工发布提交,无需为发布编辑专门的发布接口文件。
数据清洗
采集软件提供了强悍的数据清洗功能模块,可以灵活实现对采集结果数据的二次加工处理。
数据二次加工
提供了强悍的数据二次加工功能模块,可以灵活实现对采集结果数据的二次加工处理。
全程可视化鼠标操作
全程鼠标操作,用户无需使用复杂的正则表达式技术,用户都无需过问网页源码内容。
采集复杂的对象集合
采集对象的各项子内容可以是分散在多个页面内,这些内容页面可以是需要很多次链接才能到达。
多维度复杂数据采集
支持一父多子的数据关系表。子表内容可以是多项(指重复子项),也可以是父表内容的切割表。
强悍的抗干扰能力
充分利用仿浏览器解析技术,能够有效应对穿透各种反爬虫,突破绝大多数站点/网页反爬虫技术屏障。
适用场景
舆情监控
全方位监测公开信息,第一时间获取舆论趋势
市场分析
获取用户真实行为数据,全面把握顾客真实需求
产品研发
强力支撑用户调研,精准获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
透过信息洞察真相,借助数据把握规律
适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种行业需求
常见问题列表
如您关心的问题没有列出,欢迎致电 400-858-0933 进一步咨询。
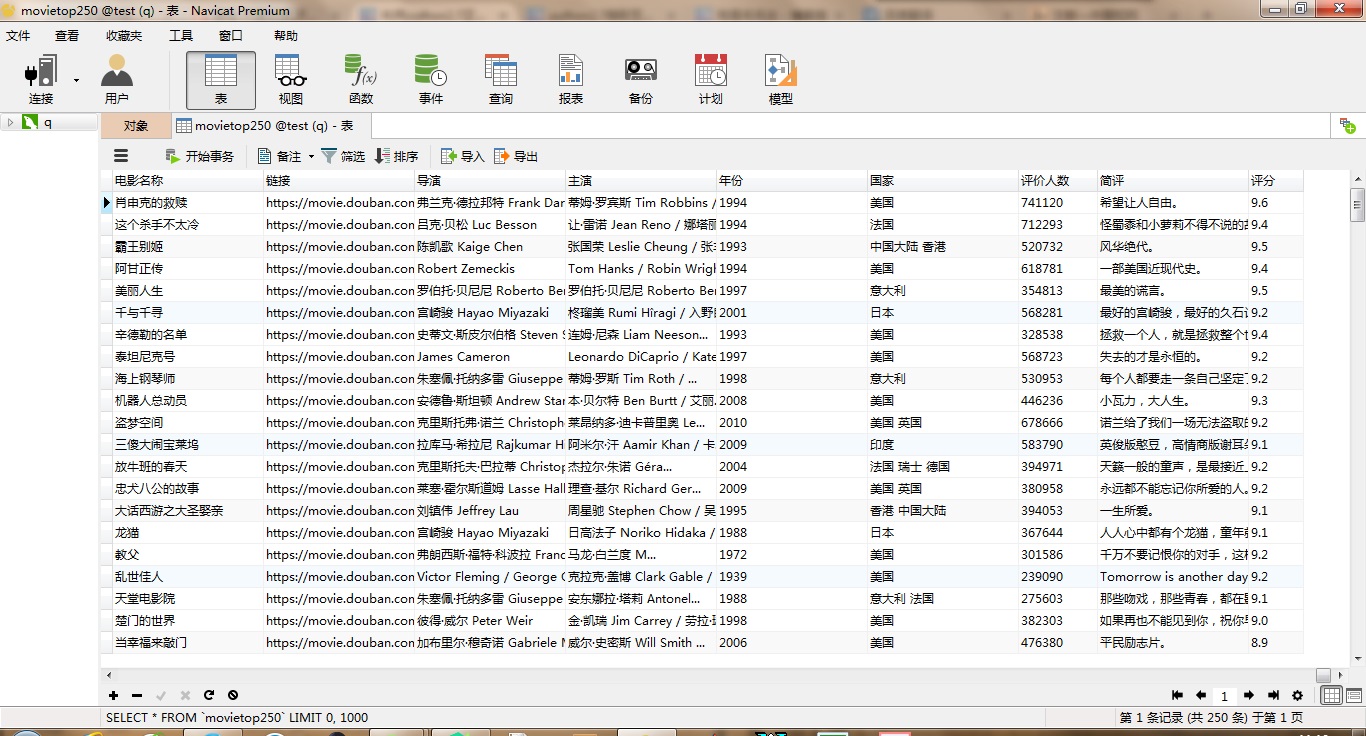
可以采集页面或网页源码中所有能见的元素信息。
支持采集视频的链接地址(URL),然后通过其他下载工具(如迅雷)下载视频。
其操作方法与图片的采集类似,但又有区别。视频URL一般都需要查看网页源码,找到对应的地址后,手写xpath。
在简易采集中有百度地图,搜狗地图等采集模版,可直接使用。
在地图搜索关键字出现的文本信息是可以抓取的,采集规则依旧是翻页列表采集的规则。地图网页如果是FLASH网页,则无法对FLASH网页进行采集。
可以。本地采集同时开启的任务数官方并未对此作出限制。但能开启的任务数受自身电脑配置、网速、网站的影响,其中电脑配置影响最大。此外不建议同时开启太多任务。
旗舰版云采集最多支持十个任务同时运行,但是这样速度有可能很慢。故不建议同时开启过多的任务。
对没有权限查看的匿名数据,是不可以采集的,我们不会协助收集没有权限浏览的数据,比如别人的密码等隐私数据。
不需要。本系统采用Web开发技术,可以在任何能够联网的设备(电脑、手机、平板等)运行,只需打开网页浏览器,就可以方便地进行操作管理。
您可将数据存储在本地电脑,也可存储于我公司提供的免费存储空间当中。
并且在任何时候,您都可自由地在二者间进行切换。
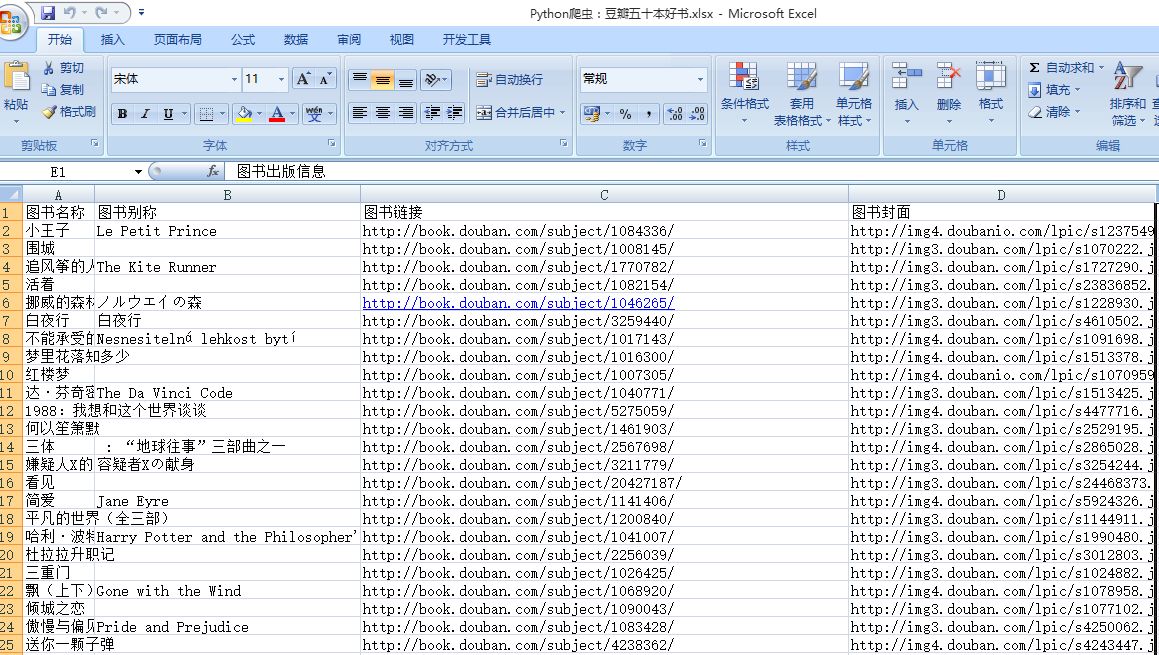
本系统可以将数据一键导入出为WORD、EXCEL、JPEG、TIF、PDF等多种格式,充分满足您的使用需求。
可以。本系统具有验证码智能识别功能,借助大数据算法,能够针对多数图形验证码进行有效识别。
对于少量无法识别的图形验证码,或其他无法通过验证的情况,我们会为您定制个性化解决方案,保证您能获取相应数据和信息。
以下情况,有可能导致采集失败:
- 目标站点服务器临时或永久性故障(即使在浏览器中输入该站点网址也无法正常访问);
- 目标站点数据页面进行了改版,数据呈现布局有所变化;
- 目标站点更新的访问验证机制。
如果多次出现“采集失败”的提示,请联系客服人员,协助您排查原因,解决问题。
可在[系统设置]-[黑名单设置]中,增加过滤关键词,包括该词语的信息和数据就不会再被采集。
如果您是企业用户,且购买了多个用户授权,则可多人同时登录,通过设置不同的规则,实现每个用户获取各自所需的数据。
如果您是个人用户,同一时刻仅可在一台设备上登录使用。
购买旗舰版产品的用户,我们开放所有源码,您可自行修改扩充,增加需要的功能。